|
|
||
|---|---|---|
| FScanpy | ||
| tutorial | ||
| FScanpy_Demo.ipynb | ||
| README.md | ||
| README_zh.md | ||
| pyproject.toml | ||
| setup.py | ||
README.md
FScanpy
A Machine Learning-Based Framework for Programmed Ribosomal Frameshifting Prediction
![]()
![]()
![]()
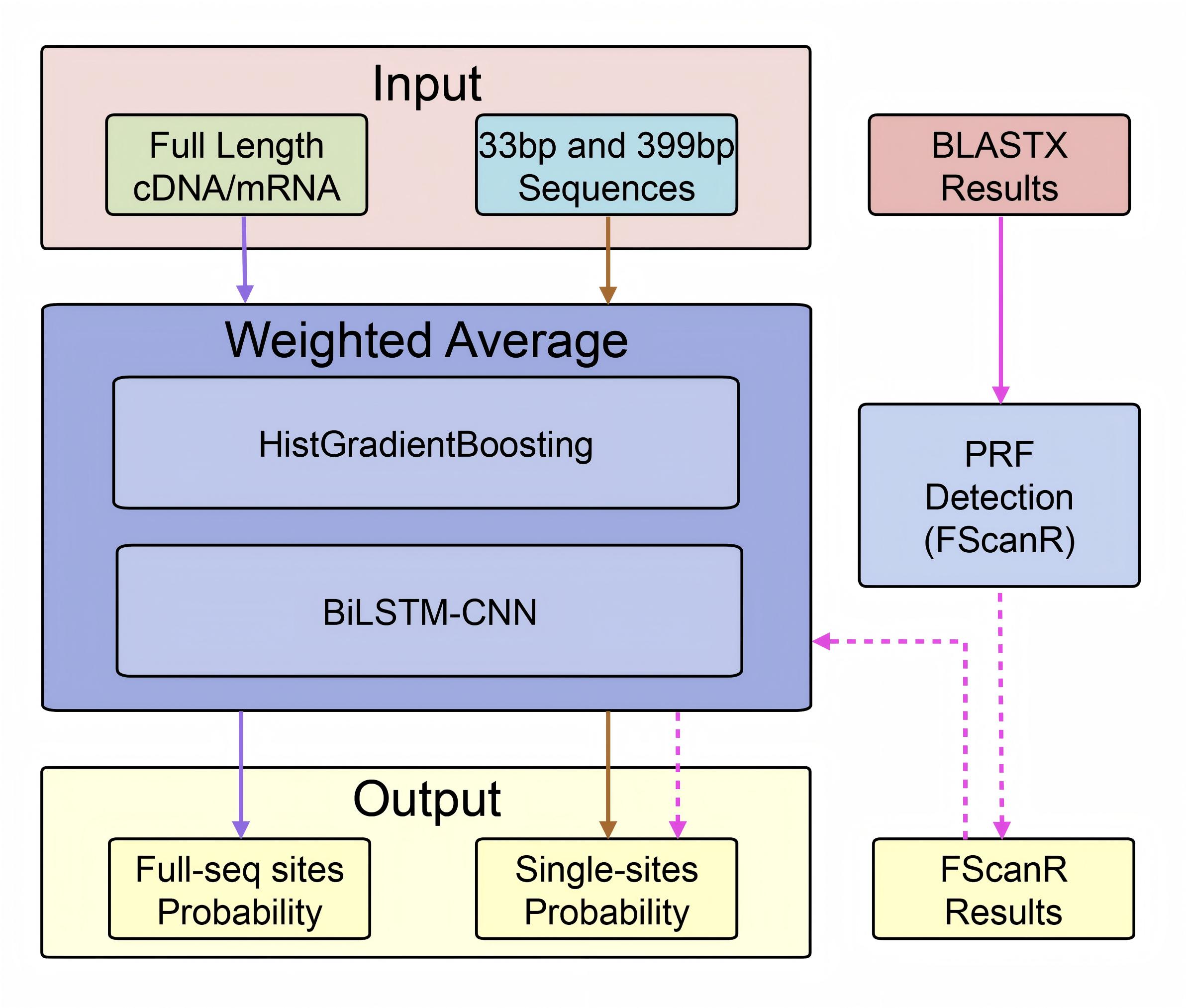
FScanpy is a comprehensive Python package designed for the prediction of Programmed Ribosomal Frameshifting (PRF) sites in nucleotide sequences. By integrating advanced machine learning approaches (HistGradientBoosting and BiLSTM-CNN) with the established FScanR framework, FScanpy provides robust and accurate PRF site predictions.
🔧 Installation
Prerequisites
- Python ≥ 3.9
- All dependencies are automatically installed
Install via pip (Recommended)
pip install FScanpy
Install from Source
git clone https://github.com/your-org/FScanpy-package.git
cd FScanpy-package
pip install -e .
🚀 Quick Start
Basic Usage
from FScanpy import predict_prf
# Simple sequence prediction
sequence = "ATGCGTACGTTAGC..." # Your DNA sequence
results = predict_prf(sequence=sequence)
# View top predictions
print(results[['Position', 'Ensemble_Probability', 'Short_Probability', 'Long_Probability']].head(10))
Visualization
from FScanpy import plot_prf_prediction
# Generate prediction plot
results, fig = plot_prf_prediction(
sequence=sequence,
short_threshold=0.65, # HistGB threshold
long_threshold=0.8, # BiLSTM-CNN threshold
ensemble_weight=0.4, # 40% Short, 60% Long
title="PRF Prediction Results"
)
Advanced Usage
from FScanpy import PRFPredictor
import pandas as pd
# Create predictor instance
predictor = PRFPredictor()
# Batch prediction on pre-extracted regions
data = pd.DataFrame({
'Long_Sequence': ['ATGCGT...' * 60, 'GCTATAG...' * 57] # 399bp sequences
})
results = predictor.predict_regions(data, ensemble_weight=0.4)
# Sequence-level prediction with custom parameters
results = predictor.predict_sequence(
sequence=sequence,
window_size=1, # Step size for sliding window
ensemble_weight=0.3, # Model weighting
short_threshold=0.5 # Filtering threshold
)
🎛️ Ensemble Weight Configuration
The ensemble_weight parameter controls the weight ratio between HistGB and BiLSTM-CNN models:
| ensemble_weight | HistGB Model | BiLSTM-CNN Model | Characteristics | Best For |
|---|---|---|---|---|
| 0.2-0.3 | 20-30% | 70-80% | High specificity, reduces false positives | Precise validation, clinical applications |
| 0.4 | 40% | 60% | Optimal balance, highest AUC | Standard analysis (recommended) |
| 0.6-0.8 | 60-80% | 20-40% | High sensitivity, captures more sites | High-throughput screening, exploratory research |
Model Characteristics
- HistGB Model: Excels at identifying true negatives, conservative predictions, low false positive rate
- BiLSTM-CNN Model: Excels at identifying true positives, sensitive predictions, captures more potential sites
Weight Selection Examples
# High specificity configuration (favoring HistGB)
precise_results = predict_prf(sequence, ensemble_weight=0.25)
# Optimal balance configuration (4:6 ratio)
balanced_results = predict_prf(sequence, ensemble_weight=0.4)
# High sensitivity configuration (favoring BiLSTM-CNN)
sensitive_results = predict_prf(sequence, ensemble_weight=0.7)
📊 Core Functions
Main Prediction Interface
predict_prf(
sequence=None, # Single/multiple sequences or None
data=None, # DataFrame with 399bp sequences or None
window_size=3, # Sliding window step size
short_threshold=0.1, # Short model filtering threshold
ensemble_weight=0.4, # Short model weight (0.0-1.0)
model_dir=None # Custom model directory
)
Visualization Function
plot_prf_prediction(
sequence, # Input DNA sequence
window_size=3, # Scanning step size
short_threshold=0.65, # Short model threshold for plotting
long_threshold=0.8, # Long model threshold for plotting
ensemble_weight=0.4, # Model weighting
title=None, # Plot title
save_path=None, # Save file path
figsize=(12,8), # Figure size
dpi=300 # Resolution for saved plots
)
PRFPredictor Class Methods
predictor = PRFPredictor()
# Sequence prediction (sliding window)
predictor.predict_sequence(sequence, ensemble_weight=0.4)
# Region prediction (batch processing)
predictor.predict_regions(dataframe, ensemble_weight=0.4)
# Feature extraction
predictor.extract_features(sequences)
# Model information
predictor.get_model_info()
📈 Output Fields
Prediction Results
Position: Position in the original sequenceEnsemble_Probability: Final ensemble prediction (main result)Short_Probability: HistGradientBoosting prediction (0-1)Long_Probability: BiLSTM-CNN prediction (0-1)Ensemble_Weights: Model weight configuration used
Sequence Information
Short_Sequence: 33bp sequence for Short modelLong_Sequence: 399bp sequence for Long modelCodon: 3bp codon at the prediction positionSequence_ID: Identifier for multi-sequence inputs
🔬 Integration with FScanR
FScanpy works seamlessly with the FScanR pipeline for comprehensive PRF analysis:
from FScanpy import fscanr, extract_prf_regions, predict_prf
# Step 1: BLASTX analysis with FScanR
blastx_results = fscanr(
blastx_data,
mismatch_cutoff=10,
evalue_cutoff=1e-5,
frameDist_cutoff=10
)
# Step 2: Extract PRF candidate regions
prf_regions = extract_prf_regions(original_sequence, blastx_results)
# Step 3: Predict with FScanpy
final_predictions = predict_prf(data=prf_regions, ensemble_weight=0.4)
📚 Documentation
- Complete Tutorial: Comprehensive usage guide with examples
- Demo Notebook: Practical usage of each function in the library and demonstration of analysis workflow results
- Predict Sample Interpretation: Detailed interpretation of FScanpy's plotting results and signal analysis
📝 Citation
If you use FScanpy in your research, please cite:
🏗️ Dependencies
FScanpy automatically installs all required dependencies:
numpy>=1.24.3pandas>=2.2.3tensorflow>=2.10.1scikit-learn>=1.6.0matplotlib>=3.9.4joblib>=1.4.2biopython>=1.85wrapt>=1.17.0
FScanpy - Advancing programmed ribosomal frameshifting research through machine learning 🧬