|
|
||
|---|---|---|
| FScanpy | ||
| tutorial | ||
| FScanpy_Demo.ipynb | ||
| README.md | ||
| example_plot_prediction.py | ||
| predict_sample.ipynb | ||
| pyproject.toml | ||
| setup.py | ||
README.md
FScanpy
A Machine Learning-Based Framework for Programmed Ribosomal Frameshifting Prediction
![]()
![]()
FScanpy is a comprehensive Python package designed for the prediction of Programmed Ribosomal Frameshifting (PRF) sites in nucleotide sequences. By integrating advanced machine learning approaches (HistGradientBoosting and BiLSTM-CNN) with the established FScanR framework, FScanpy provides robust and accurate PRF site predictions.
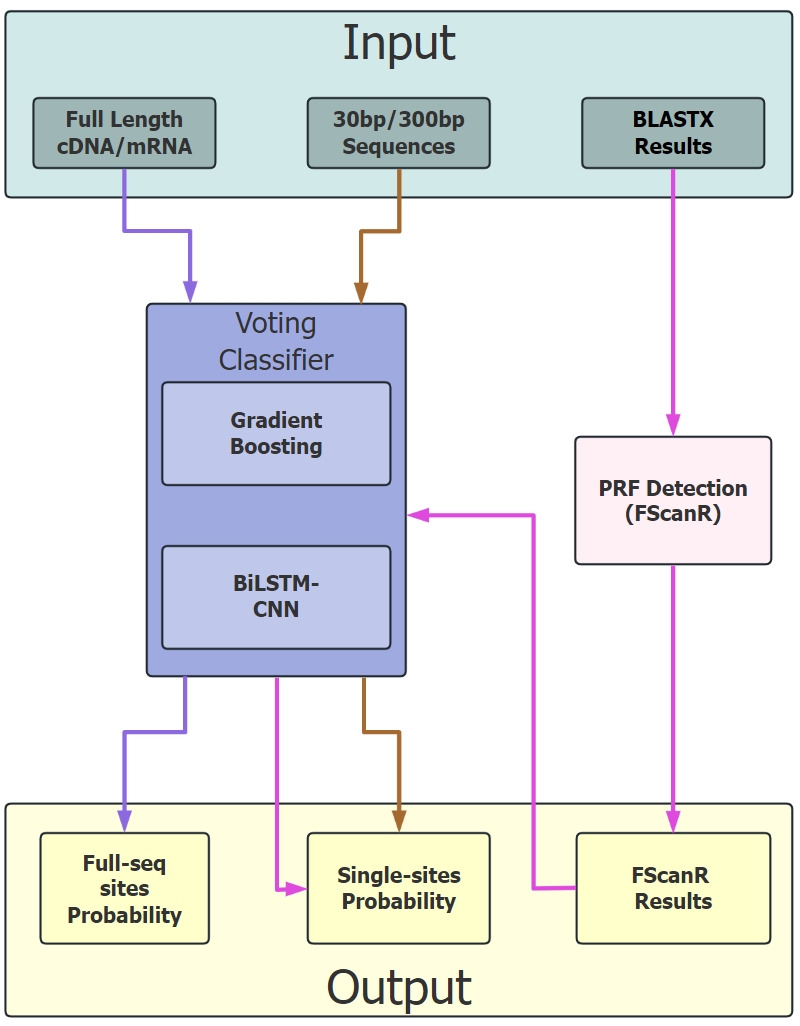
🌟 Key Features
🎯 Dual-Model Architecture
- Short Model (
HistGradientBoosting): Fast screening with 33bp sequences - Long Model (
BiLSTM-CNN): Deep analysis with 399bp sequences - Ensemble Prediction: Customizable model weights for optimal performance
🚀 Versatile Input Support
- Single/Multiple Sequences: Sliding window prediction across full sequences
- Region-Based Analysis: Direct prediction on pre-extracted 399bp regions
- BLASTX Integration: Seamless workflow with FScanR pipeline
- Cross-Species Compatibility: Built-in databases for viruses, marine phages, Euplotes, etc.
📊 Advanced Visualization
- Interactive Heatmaps: FS site probability visualization
- Prediction Plots: Combined probability and confidence displays
- Customizable Thresholds: Separate filtering for each model
- Export Options: PNG, PDF, and interactive formats
⚡ High Performance
- Optimized Algorithms: Efficient sliding window scanning
- Batch Processing: Handle multiple sequences simultaneously
- Flexible Thresholds: Tunable sensitivity for different use cases
- Memory Efficient: Optimized for large-scale genomic data
🔧 Installation
Prerequisites
- Python ≥ 3.7
- All dependencies are automatically installed
Install via pip (Recommended)
pip install FScanpy
Install from Source
git clone https://github.com/your-org/FScanpy-package.git
cd FScanpy-package
pip install -e .
🚀 Quick Start
Basic Usage
from FScanpy import predict_prf
# Simple sequence prediction
sequence = "ATGCGTACGTTAGC..." # Your DNA sequence
results = predict_prf(sequence=sequence)
# View top predictions
print(results[['Position', 'Ensemble_Probability', 'Short_Probability', 'Long_Probability']].head(10))
Visualization
from FScanpy import plot_prf_prediction
# Generate prediction plot
results, fig = plot_prf_prediction(
sequence=sequence,
short_threshold=0.65, # HistGB threshold
long_threshold=0.8, # BiLSTM-CNN threshold
ensemble_weight=0.4, # 40% Short, 60% Long
title="PRF Prediction Results"
)
Advanced Usage
from FScanpy import PRFPredictor
import pandas as pd
# Create predictor instance
predictor = PRFPredictor()
# Batch prediction on pre-extracted regions
data = pd.DataFrame({
'Long_Sequence': ['ATGCGT...' * 60, 'GCTATAG...' * 57] # 399bp sequences
})
results = predictor.predict_regions(data, ensemble_weight=0.4)
# Sequence-level prediction with custom parameters
results = predictor.predict_sequence(
sequence=sequence,
window_size=1, # Step size for sliding window
ensemble_weight=0.3, # Model weighting
short_threshold=0.5 # Filtering threshold
)
🎛️ Ensemble Weight Configuration
The ensemble_weight parameter controls the contribution of each model:
| ensemble_weight | Short Model | Long Model | Best For |
|---|---|---|---|
| 0.2-0.3 | 20-30% | 70-80% | High sensitivity, detecting subtle sites |
| 0.4-0.5 | 40-50% | 50-60% | Balanced detection (recommended) |
| 0.6-0.7 | 60-70% | 30-40% | Fast screening, high specificity |
Weight Selection Examples
# High sensitivity (Long model dominant)
sensitive_results = predict_prf(sequence, ensemble_weight=0.2)
# Balanced approach (recommended)
balanced_results = predict_prf(sequence, ensemble_weight=0.4)
# Fast screening (Short model dominant)
screening_results = predict_prf(sequence, ensemble_weight=0.7)
📊 Core Functions
Main Prediction Interface
predict_prf(
sequence=None, # Single/multiple sequences or None
data=None, # DataFrame with 399bp sequences or None
window_size=3, # Sliding window step size
short_threshold=0.1, # Short model filtering threshold
ensemble_weight=0.4, # Short model weight (0.0-1.0)
model_dir=None # Custom model directory
)
Visualization Function
plot_prf_prediction(
sequence, # Input DNA sequence
window_size=3, # Scanning step size
short_threshold=0.65, # Short model threshold for plotting
long_threshold=0.8, # Long model threshold for plotting
ensemble_weight=0.4, # Model weighting
title=None, # Plot title
save_path=None, # Save file path
figsize=(12,8), # Figure size
dpi=300 # Resolution for saved plots
)
PRFPredictor Class Methods
predictor = PRFPredictor()
# Sequence prediction (sliding window)
predictor.predict_sequence(sequence, ensemble_weight=0.4)
# Region prediction (batch processing)
predictor.predict_regions(dataframe, ensemble_weight=0.4)
# Feature extraction
predictor.extract_features(sequences)
# Model information
predictor.get_model_info()
📈 Output Fields
Prediction Results
Position: Position in the original sequenceEnsemble_Probability: Final ensemble prediction (main result)Short_Probability: HistGradientBoosting prediction (0-1)Long_Probability: BiLSTM-CNN prediction (0-1)Ensemble_Weights: Model weight configuration used
Sequence Information
Short_Sequence: 33bp sequence for Short modelLong_Sequence: 399bp sequence for Long modelCodon: 3bp codon at the prediction positionSequence_ID: Identifier for multi-sequence inputs
🔬 Integration with FScanR
FScanpy works seamlessly with the FScanR pipeline for comprehensive PRF analysis:
from FScanpy import fscanr, extract_prf_regions, predict_prf
# Step 1: BLASTX analysis with FScanR
blastx_results = fscanr(
blastx_data,
mismatch_cutoff=10,
evalue_cutoff=1e-5,
frameDist_cutoff=10
)
# Step 2: Extract PRF candidate regions
prf_regions = extract_prf_regions(original_sequence, blastx_results)
# Step 3: Predict with FScanpy
final_predictions = predict_prf(data=prf_regions, ensemble_weight=0.4)
📚 Documentation
- Complete Tutorial: Comprehensive usage guide with examples
- Demo Notebook: Interactive examples and workflows
- Example Scripts: Ready-to-run code examples
🎯 Use Cases
1. Viral Genome Analysis
# Scan viral genome for PRF sites
viral_sequence = load_viral_genome()
prf_sites = predict_prf(viral_sequence, ensemble_weight=0.3)
high_confidence = prf_sites[prf_sites['Ensemble_Probability'] > 0.8]
2. Comparative Genomics
# Compare PRF patterns across species
species_data = pd.DataFrame({
'Species': ['Virus_A', 'Virus_B'],
'Long_Sequence': [seq_a_399bp, seq_b_399bp]
})
comparative_results = predict_prf(data=species_data)
3. High-Throughput Screening
# Fast screening of large sequence datasets
sequences = load_large_dataset()
screening_results = predict_prf(
sequence=sequences,
ensemble_weight=0.7, # Fast screening mode
short_threshold=0.3
)
🤝 Contributing
We welcome contributions! Please see our Contributing Guidelines for details.
📝 Citation
If you use FScanpy in your research, please cite:
@software{fscanpy2024,
title={FScanpy: A Machine Learning Framework for Programmed Ribosomal Frameshifting Prediction},
author={[Author names]},
year={2024},
url={https://github.com/your-org/FScanpy}
}
📄 License
This project is licensed under the MIT License - see the LICENSE file for details.
🆘 Support
- Issues: GitHub Issues
- Documentation: Tutorial
- Examples: Demo Notebook
🏗️ Dependencies
FScanpy automatically installs all required dependencies:
numpy>=1.24.3pandas>=2.2.3tensorflow>=2.10.1scikit-learn>=1.6.0matplotlib>=3.9.4joblib>=1.4.2biopython>=1.85wrapt>=1.17.0
FScanpy - Advancing programmed ribosomal frameshifting research through machine learning 🧬